
Why the Quality of Archive Storage Boxes Matters More Than You Think
There’s a document somewhere in your organisation that would answer the exact question you’re trying to answer right now. Maybe it’s a 2019 contract. A research report from a consultant you no longer work with, a policy memo buried in a shared drive folder that hasn’t been opened in three years.
The problem isn’t that it doesn’t exist. The problem is that you’ll never find it.
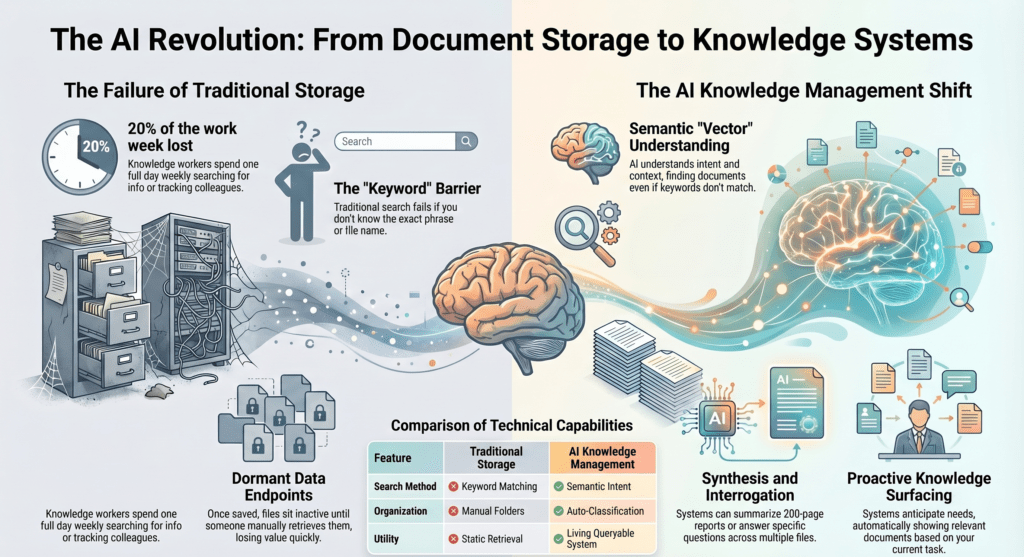
According to McKinsey, knowledge workers spend nearly 20% of their working week searching for internal information or tracking down colleagues who can help them find it. That’s one full day every week, not spent on problems, but on finding the information needed to start working on them.
Generative AI is about to make this problem disappear. But the shift goes much further than better search. The future of document storage isn’t just about retrieval; it’s about turning static archives into living, queryable knowledge systems that work for you rather than against you.
Why Traditional Document Storage Is Broken
The way most organisations store documents was designed for a world where filing cabinets were physical. The logic mapped onto digital systems: folders within folders, organised by project or date or department, accessible to those who knew where to look.
This system has three fundamental flaws.
It relies on someone organising it correctly in the first place. Folder hierarchies only work when every person who saves a document follows the same logic. In practice, they don’t. Files end up duplicated across drives, named inconsistently, filed under the wrong project, or simply dumped in a generic folder and forgotten.
It relies on the searcher knowing what they’re looking for. Traditional search is keyword-based. If you don’t know the exact phrase that appears in the document, or what the document was even called, the search fails. You can’t ask a file system a question. You can only ask it for terms it can match.
It treats documents as endpoints rather than assets. Once a file is saved, it sits dormant until someone manually retrieves it. There’s no intelligence sitting on top of that archive. It doesn’t know what’s in there, what’s relevant, or what might help you.
The result is organisations that generate enormous amounts of knowledge and then effectively “lose” it within months.

What Generative AI Actually Does to Documents
Generative AI doesn’t just improve search. It changes the relationship between people and information.
Natural language queries replace keyword hunting. Instead of searching for “penalty clause contract 2019 Johnson”, you can ask: “Do any of our supplier contracts include penalty clauses triggered by delivery delays of more than five days?” The system understands what you mean and retrieves what’s relevant , even if the document uses different terminology.
Documents can be summarised, synthesised and interrogated. A 200-page due diligence report can be condensed to a two-page brief. Fifty customer feedback forms can be synthesised into a thematic analysis. A legal agreement can be interrogated: “What are our termination rights under this contract?”
New documents can be generated from existing ones. AI systems that understand your document archive can produce first drafts that draw on your institutional knowledge , proposals that reference past project outcomes, reports that pull in relevant data, briefs that incorporate previous research.
Metadata and classification happen automatically. Rather than relying on humans to tag and categorise documents correctly, AI can read the content and apply metadata at scale , identifying document type, subject matter, relevant entities, dates and relationships to other files.
This is the shift from document management to knowledge management. The difference matters. Document management is administrative. Knowledge management is strategic.
The Rise of Smart Archive Search
The term “smart archive search” is becoming one of the more significant capabilities in enterprise software , and it’s worth understanding what actually makes it smart.
Traditional search engines match keywords. Smart archive search uses semantic understanding, the ability to grasp meaning, context and intent, not just exact phrasing.
The technology behind this is called vector embeddings. When a document is ingested into a modern AI-powered system, it isn’t just indexed by keywords. The system creates a mathematical representation of the document’s meaning, a vector, that captures the concepts, relationships and context within it. When you search, your query is converted into a similar vector, and the system finds documents whose meaning is closest to yours.
In practical terms, this means:
- A search for “employee dismissal process” will surface a document titled “Staff Termination Procedure” even if neither word appears in the other
- A question about “what we agreed with Accenture about data governance” will surface the relevant section of a contract, not just the contract as a whole
- A search for “how we handled the Sheffield warehouse problem last year” will pull up relevant email threads, incident reports and internal memos even if none of them use those exact words
The industries that stand to gain most immediately are those with dense, high-value document archives: legal, financial services, healthcare, consulting and professional services. But the shift is broader than that. Any organisation that generates significant institutional knowledge and struggles to retain and access it is a candidate.
AI Knowledge Management: Beyond Just Finding Files
The most forward-thinking organisations are moving past the question of search entirely. They’re asking a different question: what if the right information reached the right person before they even searched for it?
This is the promise of AI knowledge management: systems that don’t just respond to queries but actively surface relevant knowledge based on context.
Knowledge graphs connect documents by meaning rather than metadata. Instead of a flat archive of files, you get a web of relationships: this contract is connected to this supplier, whose performance data is stored here, alongside the email thread where concerns were raised and the board paper where the decision was reviewed. When you pull one thread, the system surfaces the others.
Proactive surfacing uses context signals to anticipate information needs. A salesperson opening a CRM record for a client might automatically see the last proposal sent, the service issues raised, and relevant case studies, all pulled from different systems and surfaced without any manual search.
Gap identification flags knowledge that should exist but doesn’t. If your AI system notices that every project in your archive has a lessons-learned document except the three largest ones, it can flag that. If it detects that a policy referenced in ten documents hasn’t been updated in four years, it can surface that for review.
Duplication reduction finds documents that are substantively the same and merges or links them. In large organisations, the same analysis is often conducted multiple times by people who didn’t know the first one existed. AI knowledge management can make that visible.
The cumulative effect of these capabilities is significant. Instead of a growing archive that becomes progressively harder to navigate, you get an organisational memory that becomes more useful over time.
What Smart Document Management Tools Look Like Today
The market for AI-powered document management is moving quickly. Here’s what to look for when evaluating smart document management tools.
Semantic search as a baseline. Any tool worth considering should offer semantic search , natural language querying that understands meaning, not just keywords. If a vendor is still leading with Boolean search as a feature, look elsewhere.
Summarisation and extraction. The ability to generate summaries, extract key clauses, answer specific questions from within documents, and synthesise across multiple files.
Auto-classification and tagging. AI-driven metadata generation that reduces the burden on users to manually categorise documents. Look for configurable taxonomy support , the system should be able to learn your organisation’s specific categories and terminology.
Access controls and audit trails. Particularly important for regulated industries. Smart doesn’t mean unsecured. The system needs to respect permissions, log access, and provide clear audit trails for compliance purposes.
Integration with existing workflows. A document management system that requires people to change how they work will face adoption challenges. The best tools integrate with the software already in use , Microsoft 365, Google Workspace, Slack, Salesforce, legal practice management systems, and so on.
Source citation. When AI surfaces or synthesises information, it should be traceable. Users need to be able to see which document, clause or source an answer is drawn from , both for accuracy and for compliance reasons.
Current deployments are concentrated in legal, financial services and large enterprises, but the tooling is maturing quickly. Mid-market products are emerging that bring these capabilities to smaller teams without the implementation cost of enterprise platforms.
The Challenges Worth Taking Seriously
No honest discussion of AI in document systems is complete without addressing the risks.
Hallucination and confident inaccuracy. Large language models can generate plausible-sounding answers that are wrong. In a document management context, this means a system might confidently surface an answer drawn from an outdated version of a policy, or misquote a contract clause. The mitigation is source transparency , any AI answer should be traceable to the specific document it came from, and users should be trained to verify high-stakes information.
Privacy and compliance. AI systems that can read and query all your documents will, by definition, expose those documents to the model. For organisations handling sensitive personal data, confidential client information, or regulated data, this creates real compliance questions around GDPR, data residency, and attorney-client privilege. Architecture matters enormously here , where does the model run? Is data used for training? Who has access?
Change management. The technology is often the easier problem. Getting people to trust, adopt and properly use a new system is harder. Organisations that treat AI document management as a software deployment rather than a behavioural change programme tend to see low adoption.
Over-reliance and deskilling. There is a risk that easy access to AI-synthesised answers reduces the incentive to deeply understand source material. Particularly in knowledge-intensive professions, this is worth monitoring carefully.
None of these challenges are reasons not to adopt AI in document systems. They are reasons to adopt thoughtfully, with appropriate governance, testing and training in place.
What Comes Next
The current generation of AI document tools is impressive, but it represents an early stage. Here’s where the capability curve is heading.
Predictive document creation. Rather than searching for a document and then writing something new, AI will begin anticipating what needs to be created. After a client meeting, a system might automatically draft a summary and suggested follow-up actions. After a project closes, it might generate a lessons-learned document based on the communications, decisions and outcomes it can see in the archive.
Multimodal archives. Today’s AI-powered search is largely text-based. The next wave will handle images, audio and video with the same semantic understanding , allowing searches that surface insights from recorded meetings, scanned handwritten notes, presentation slide decks, and visual reports.
Autonomous document agents. Beyond search and summarisation, AI agents will be able to take action on documents: routing contracts for signature, flagging renewal dates, identifying compliance gaps, generating required reports, and updating records based on new information.
The organisation as a living knowledge system. The longer-term vision is an organisation where institutional knowledge doesn’t decay when people leave, where the right information reaches people at the right moment, and where the collective learning of every project and every interaction is preserved and accessible. Documents stop being endpoints and become part of a continuous, queryable record of how an organisation thinks and operates.
What to Do Now
The gap between organisations that manage their knowledge well and those that don’t is already significant. The AI tools that are emerging will widen it further, and quickly.
Here are three immediate steps worth taking:
Audit where your knowledge currently lives. Map the document systems, shared drives, email archives and collaboration tools your organisation uses. Identify where high-value knowledge is being created and whether it’s being captured in a form that makes it accessible.
Identify your highest-value retrieval problems. Where does your team spend the most time searching for information? Where has lost or hard-to-find knowledge cost you time, money or quality? These are the starting points for AI document system investment.
Evaluate current tools against semantic search capability. If your document management tools only offer keyword search, you’re already behind. Most established vendors are adding AI capabilities, and a generation of purpose-built AI knowledge management tools are now available for evaluation.
The future of document storage isn’t a better filing cabinet. It’s an organisation that knows what it knows.


